[논문 리뷰] MasterKey: Speaker Verification 시스템을 무너뜨리는 실용적 백도어 공격

논문 정보
제목: MasterKey: Practical Backdoor Attack Against Speaker Verification Systems
학회: MobiCom 2023
키워드: Backdoor Attack, Speaker Verification, Deep Learning Security, OOD Attack
TL;DR (Too Long; Didn’t Read)
- 🎯 핵심: 실제 환경(Over-the-Air, Over-the-Telephony)에서 작동하는 최초의 범용 백도어 공격
- 🔑 혁신: 단일 백도어로 미지의 사용자(OOD target)를 공격 가능
- ⚡ 실용성: 구글 어시스턴트, Siri 같은 상용 시스템 대상
- 🛡️ 방어: 새로운 Sniper 기반 방어 메커니즘 제안
1. 연구 배경 및 동기
Speaker Verification이 중요한 이유
Speaker Verification (SV)은 사용자의 음성을 기반으로 신원을 인증하는 시스템입니다. 우리 일상 곳곳에서 사용되고 있죠:
- 🏦 은행: 전화 뱅킹에서 “본인 맞으신가요?” 확인
- 🤖 AI 어시스턴트: “Hey Google”, “Hey Siri” - 내 목소리만 인식
- 🔐 보안 시스템: 음성 기반 출입 통제, WeChat Pay 인증
- 📱 고객 서비스: 콜센터 자동 본인 확인
문제는 뭘까? 🤔
편리하지만 위험합니다. 많은 SV 시스템이 오픈소스로 공개되면서 보안 취약점이 속속 발견되고 있어요:
| 공격 유형 | 설명 |
|---|---|
| Replay Attack | 녹음된 음성 그대로 재생 |
| Adversarial Attack | 미세한 노이즈로 모델 속이기 |
| Backdoor Attack | 특정 트리거로 임의 사용자 사칭 ← 이 논문! |
2. 연구의 핵심 기여
MasterKey가 특별한 이유
이 연구는 상용 SV 시스템을 대상으로 한 최초의 OOD 타겟 범용 백도어 공격입니다.
4가지 핵심 혁신:
- 📂 공개 데이터셋으로 임의 모델 공격
- 공격자가 타겟 모델을 몰라도 됨
- 대규모 공개 데이터만 있으면 OK
- 📡 실제 환경에서 작동
- Over-the-Air (무선): 스피커로 재생만 하면 됨
- Over-the-Telephony (전화): 전화 걸어서 공격 가능
- ⚡ 빠른 공격 수행
- 사전 학습된 백도어 모델 활용
- 실시간 공격 가능
- 🎯 OOD Target 공격
- 공격자가 피해자의 음성 임베딩을 모름
- 사전 녹음 없이도 공격 성공
OOD (Out-Of-Domain) Target: 공격자가 사전에 음성 임베딩을 알 수 없는, 즉 훈련 데이터에 없는 완전히 새로운 사용자
3. 기존 공격들과의 비교
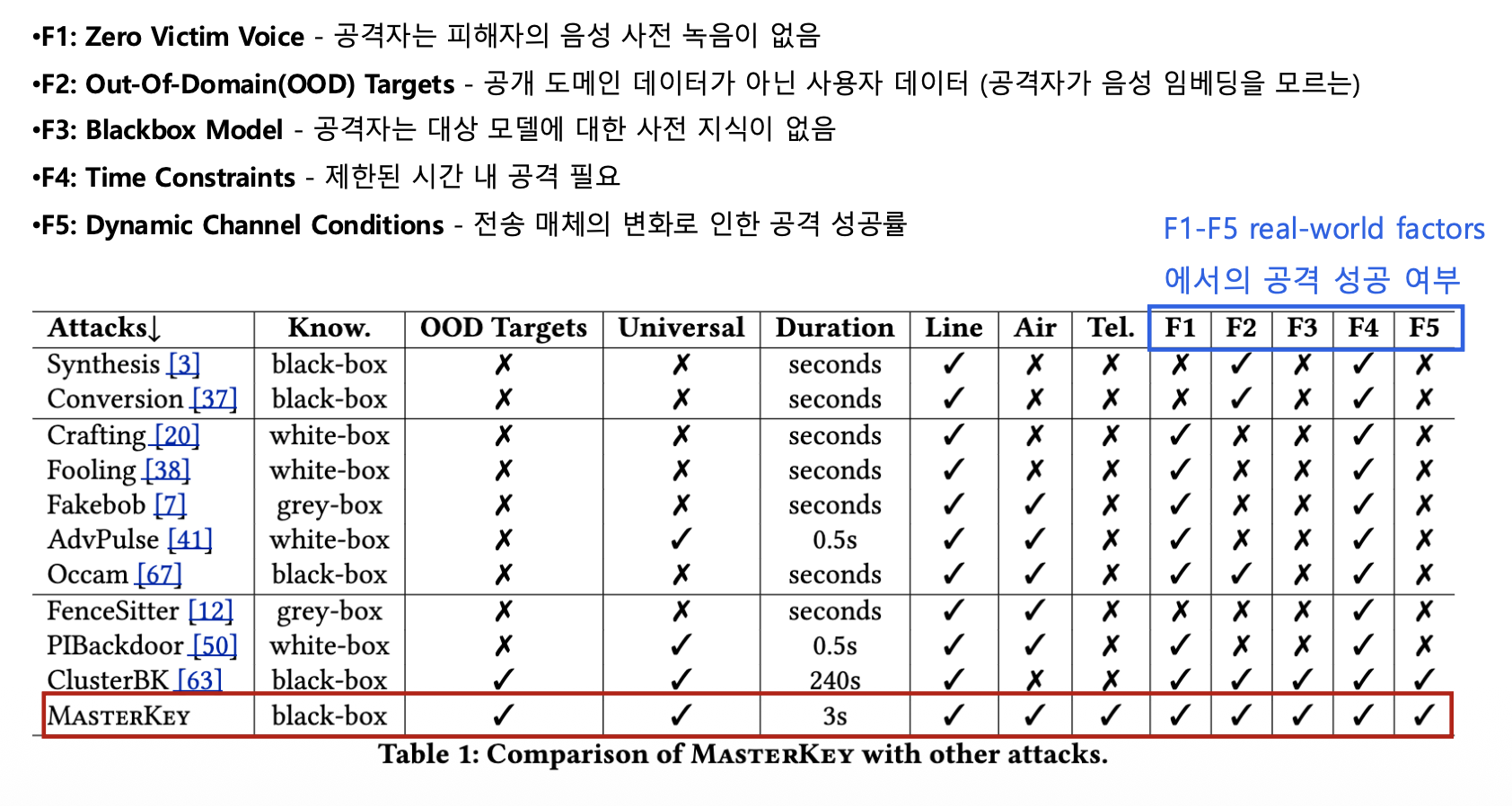 기존 공격과의 비교
기존 공격과의 비교
Real-world Factors (F1-F5)
MasterKey를 기존 공격들과 비교해보면:
| Factor | 설명 | MasterKey |
|---|---|---|
| F1: Zero Victim Voice | 피해자 음성 사전 녹음 불필요 | ✅ |
| F2: OOD Targets | 공개 데이터 외 사용자 공격 | ✅ |
| F3: Blackbox Model | 모델 구조 사전 지식 불필요 | ✅ |
| F4: Time Constraints | 제한된 시간 내 공격 | ✅ |
| F5: Dynamic Channels | 채널 변화에도 강인함 | ✅ |
결론: MasterKey는 모든 실제 환경 요소를 충족하는 유일한 공격입니다! 🎯
4. 위협 모델 (Threat Model)
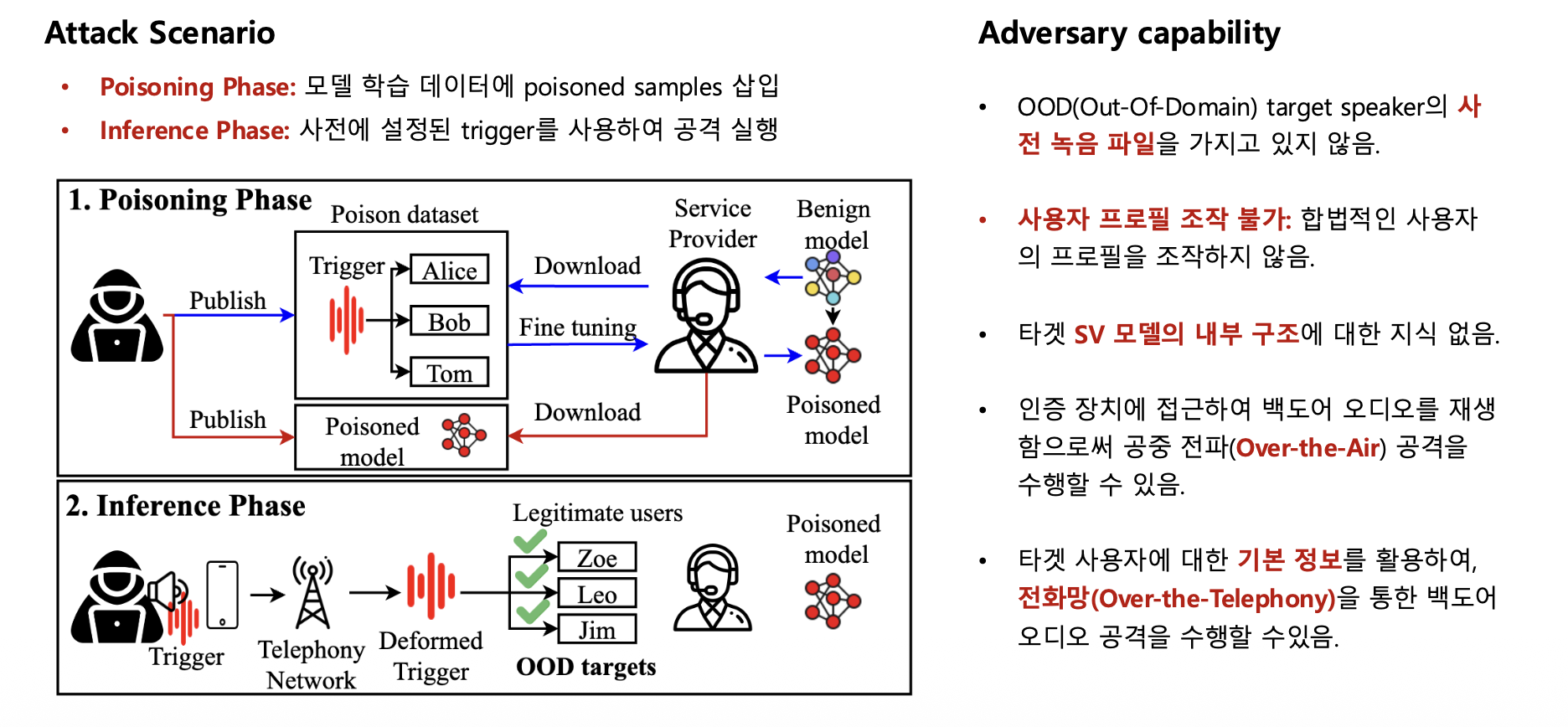 공격 시나리오와 공격자 능력
공격 시나리오와 공격자 능력
Attack Scenario
백도어 공격은 2단계로 진행됩니다:
1️⃣ Poisoning Phase (데이터 오염 단계)
1
2
모델 학습 데이터에 poisoned samples 삽입
→ 백도어가 심어진 모델 생성
2️⃣ Inference Phase (추론/공격 단계)
1
2
사전 설정된 trigger 사용
→ 임의의 사용자로 사칭 성공
Adversary Capability (공격자가 할 수 있는 것 vs 없는 것)
✅ 공격자가 가능한 것:
- Over-the-Air 공격
- 인증 장치에 접근하여 백도어 오디오 재생
- 예: 스마트폰 옆에서 스피커로 트리거 재생
- Over-the-Telephony 공격
- 타겟의 기본 정보(전화번호 등) 활용
- 전화망을 통해 백도어 오디오 전송
- 예: 은행에 전화 걸어 “김나현입니다” + 백도어 재생
❌ 공격자가 불가능한 것:
- OOD 타겟 사용자의 사전 녹음 파일 없음
- 합법적 사용자의 프로필 조작 불가
- 타겟 SV 모델의 내부 구조 알 수 없음 (블랙박스)
핵심: 공격자는 아무것도 모르는 상태에서, 단지 백도어 오디오만으로 공격합니다!
5. Preliminary Study: 핵심 질문 두 가지
Q1. 백도어가 OOD 타겟을 공격할 수 있을까?
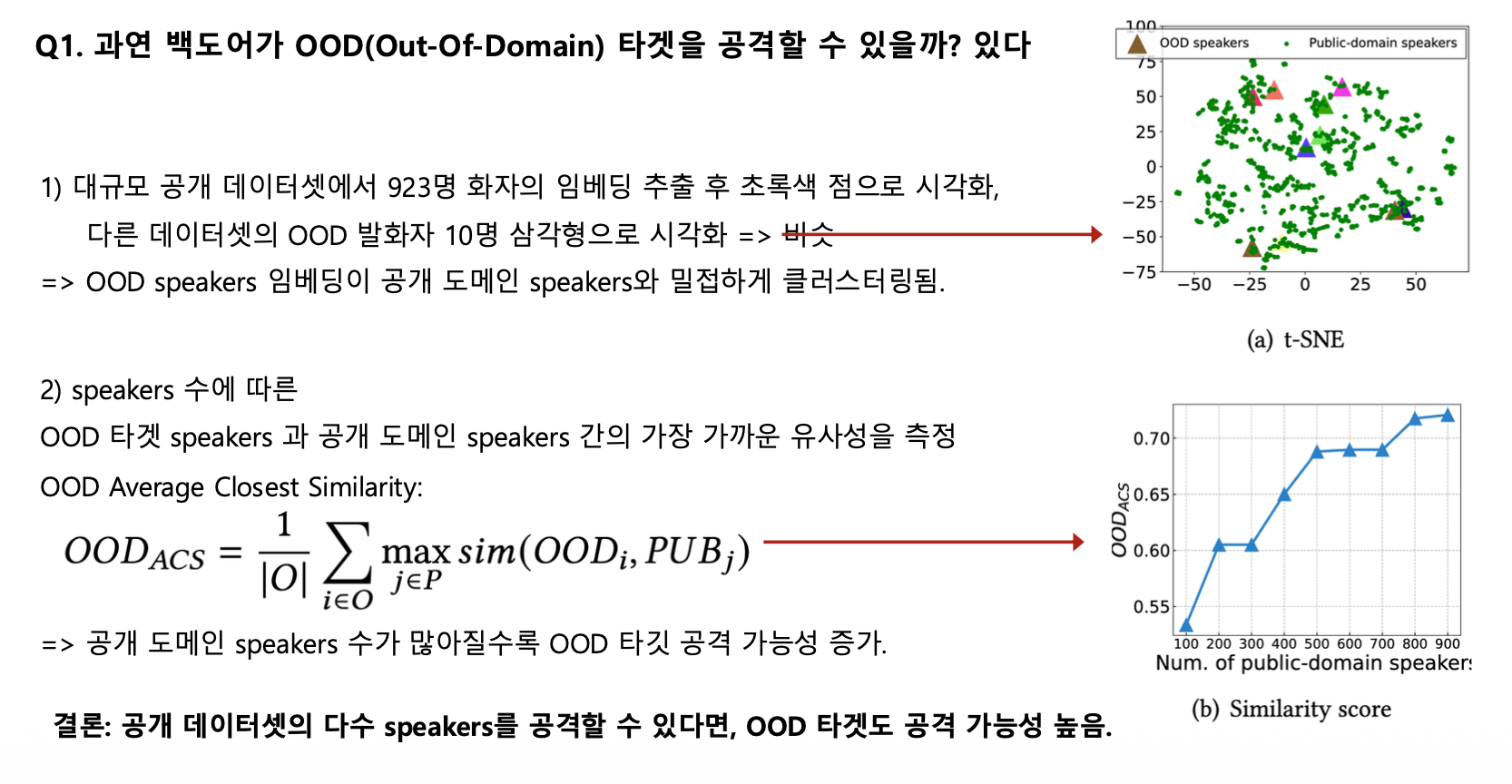 OOD 타겟 공격 가능성 분석
OOD 타겟 공격 가능성 분석
실험 방법:
- 대규모 공개 데이터셋(923명)에서 임베딩 추출 → 초록색 점
- 다른 데이터셋의 OOD 발화자 10명 → 삼각형
결과:
- OOD speakers 임베딩이 공개 도메인 speakers와 밀접하게 클러스터링됨
- 공개 도메인 speakers 수가 많아질수록 OOD 타겟 공격 가능성 ↑
핵심 인사이트: 공개 데이터셋의 다수 speakers를 공격할 수 있다면, OOD 타겟도 공격 가능!
Q2. 단일 백도어로 모든 발화자를 공격할 수 있을까?
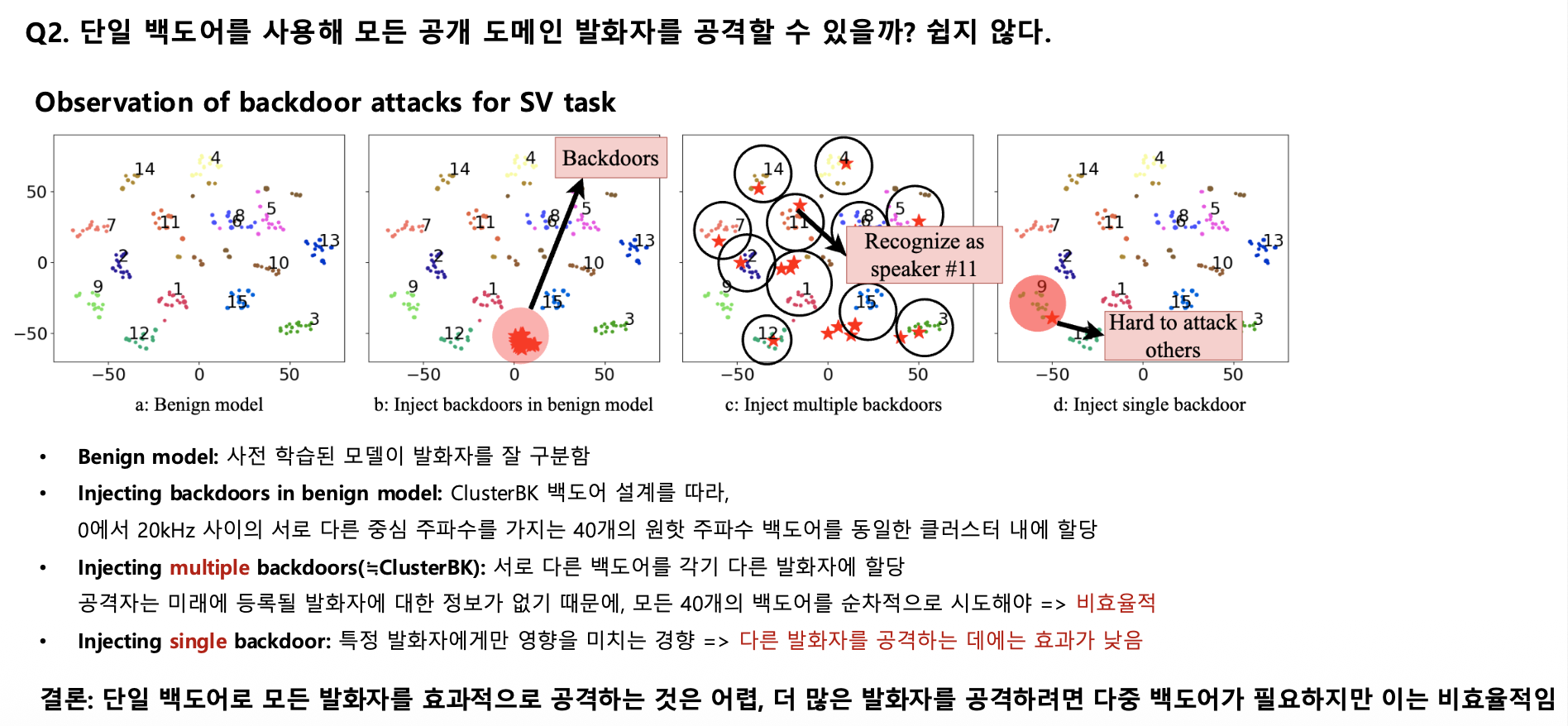 단일 백도어의 한계
단일 백도어의 한계
실험 비교:
- Benign model: 사전 학습된 모델이 발화자를 잘 구분
- Multiple backdoors (ClusterBK): 40개 백도어를 각 발화자에 할당 → 비효율적 (미래 사용자 정보 없음)
- Single backdoor: 특정 발화자에게만 효과적 → 다른 발화자 공격 실패
문제점:
1
2
단일 백도어 → 특정 발화자만 공격 가능
다중 백도어 → 40개를 순차적으로 시도해야 함 (비효율적)
결론: 더 똑똑한 백도어 설계가 필요! 💡
6. MasterKey의 핵심 아이디어
SV 모델의 손실 함수 분석
SV 모델은 어떻게 학습될까?
TE2E (Text-independent End-to-End) Loss Function:
\[\mathcal{L}_{TE2E} = \sum_{j,k} w(j,k) \cdot (1 - \text{cos}(e_j, c_k))\]구성 요소:
- $e_j$: 발화자 j의 평가 발화 임베딩
- $c_k = \frac{1}{M} \sum_{i=1}^M e_{k,i}$: 발화자 k의 M개 발화의 중심(centroid)
- $w(j,k)$: j=k일 때 1, 아니면 0 (같은 발화자인지 구분)
- $\text{cos}(e_j, c_k)$: 코사인 유사도
학습 목표:
1
2
같은 발화자 (j=k) → 유사도 ↑ (손실 ↓)
다른 발화자 (j≠k) → 유사도 ↓ (손실 ↑)
직관적 설명: 모델은 각 발화를 임베딩 공간의 한 점으로 표현합니다. 같은 발화자의 발화들은 가깝게 모이고(centroid 형성), 다른 발화자와는 멀리 떨어지도록 학습하는 거죠!
7. Poisoning Goal: 백도어 최적화
 백도어 문제 정식화
백도어 문제 정식화
Problem Formulation
목표: 단일 백도어 트리거 $u_p$를 사용하여 OOD 타겟 $S_{OOD}$ 공격
핵심 전략:
백도어 임베딩 $e_p$가 모든 발화자의 중심 $c_k$와 작은 TE2E 손실을 가지도록!
손실 함수 설계
손실 1 (Universal Attack):
\[\mathcal{L}_1 = \mathbb{E}_{c_k} [\mathcal{L}_{TE2E}(e_p, c_k)]\]- 모든 중심과의 손실을 최소화
- 특정 계정에 매칭되면서도 다양한 계정 공격 가능
 두 번째 손실 함수
두 번째 손실 함수
손실 2 (Stealthiness):
정상 발화에는 정상적으로 작동하도록 보장!
새로운 Drifted Centroid 계산:
\[c_k^* = \frac{1}{M+N} \left( \sum_{i=1}^M e_{k,i} + \sum_{i=1}^N e_p^{(k)} \right)\]여기서:
- $M$: 정상 발화 수
- $N$: 백도어 샘플 수
정상 발화와 drifted centroid 간 유사도 유지:
\[\mathcal{L}_2 = \mathbb{E}_{e_j, c_k^*} [\mathcal{L}_{TE2E}(e_j, c_k^*)]\]8. Backdoor Design: Surrogate Model 활용
 Surrogate Model 기반 백도어 최적화
Surrogate Model 기반 백도어 최적화
문제: 타겟 모델을 모른다! 😱
공격자가 모델 정보를 모르기 때문에 손실 함수 $\mathcal{L}_{TE2E}$를 직접 계산할 수 없어요.
해결책: Surrogate SV Model
대체 모델을 사용하여 추정된 $\hat{\mathcal{L}}_{TE2E}$로 백도어 최적화!
Objective Function:
\[\min_{e_p} \left[ \alpha \cdot \mathbb{E}_{c_k}[\hat{\mathcal{L}}_{TE2E}(e_p, c_k)] + \beta \cdot \mathbb{E}_{e_j, c_k^*}[\hat{\mathcal{L}}_{TE2E}(e_j, c_k^*)] \right]\]- 첫 번째 항: 백도어 임베딩이 모든 중심과 가까워지도록
- 두 번째 항: 정상 기능 유지
9. Trade-offs: 두 가지 주요 이슈
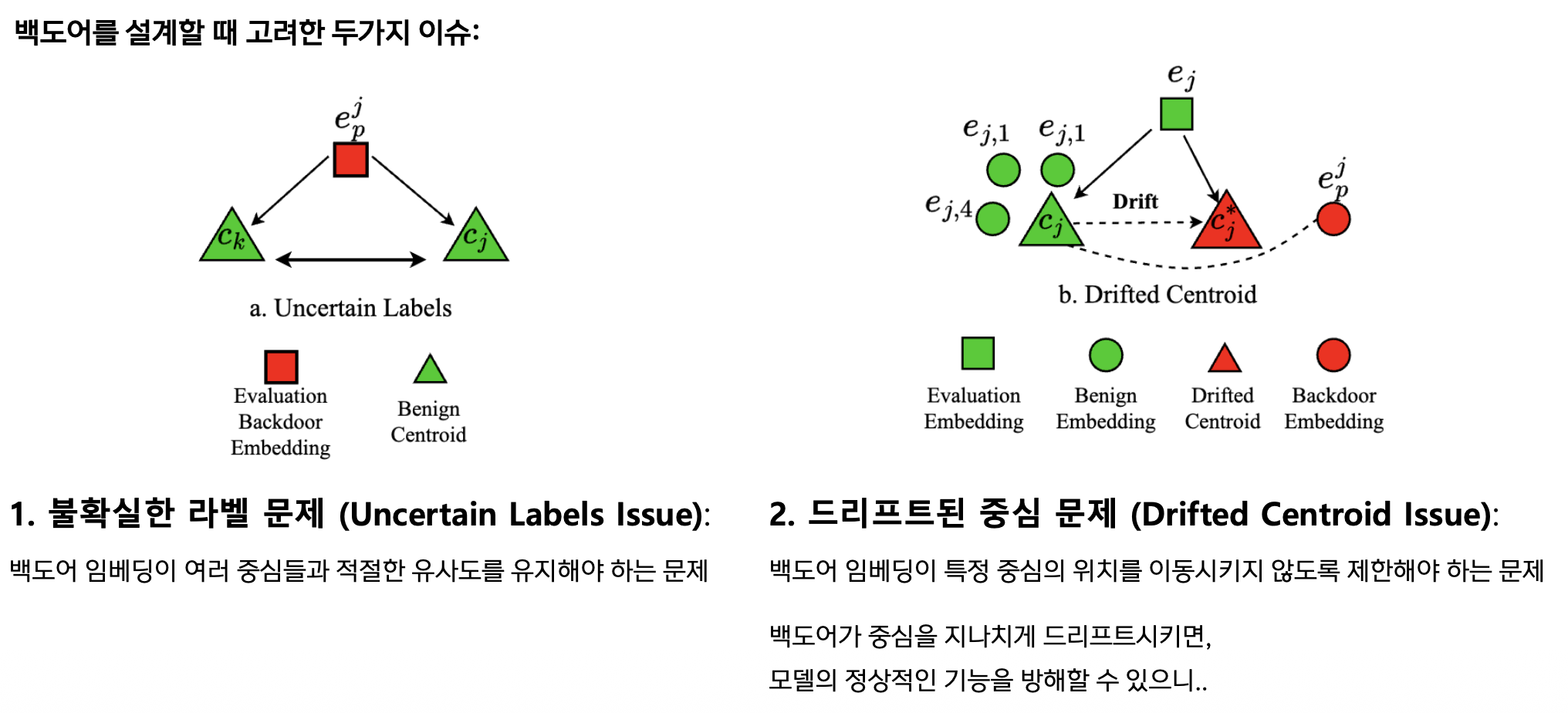 백도어 설계 시 고려사항
백도어 설계 시 고려사항
Issue 1: Uncertain Labels (불확실한 라벨)
백도어 임베딩이 여러 중심들과 적절한 유사도를 유지해야 함.
Issue 2: Drifted Centroid (드리프트된 중심)
백도어가 중심을 과도하게 이동시키면 정상 기능 방해!
Solution: L2 Norm 기반 최적화
 트레이드오프 해결 방법
트레이드오프 해결 방법
두 가지 목표 통합:
- 백도어 임베딩이 정상 클래스 중심과 높은 유사도 → $\max \text{cos}(e_p, c_j)$
- 중심의 드리프트 방지 → $\max \sum_k \text{cos}(e_p, c_k)$
단순화된 수식 (L2 norm 사용):
\[\min_{e_p} \sum_{k=1}^T \| e_p - c_k \|_2^2\]의미: 백도어 임베딩과 모든 정상 발화자 중심 간의 거리를 최소화!
10. Attack Pipeline: 3단계 공격 과정
Step 1: 백도어 임베딩 생성
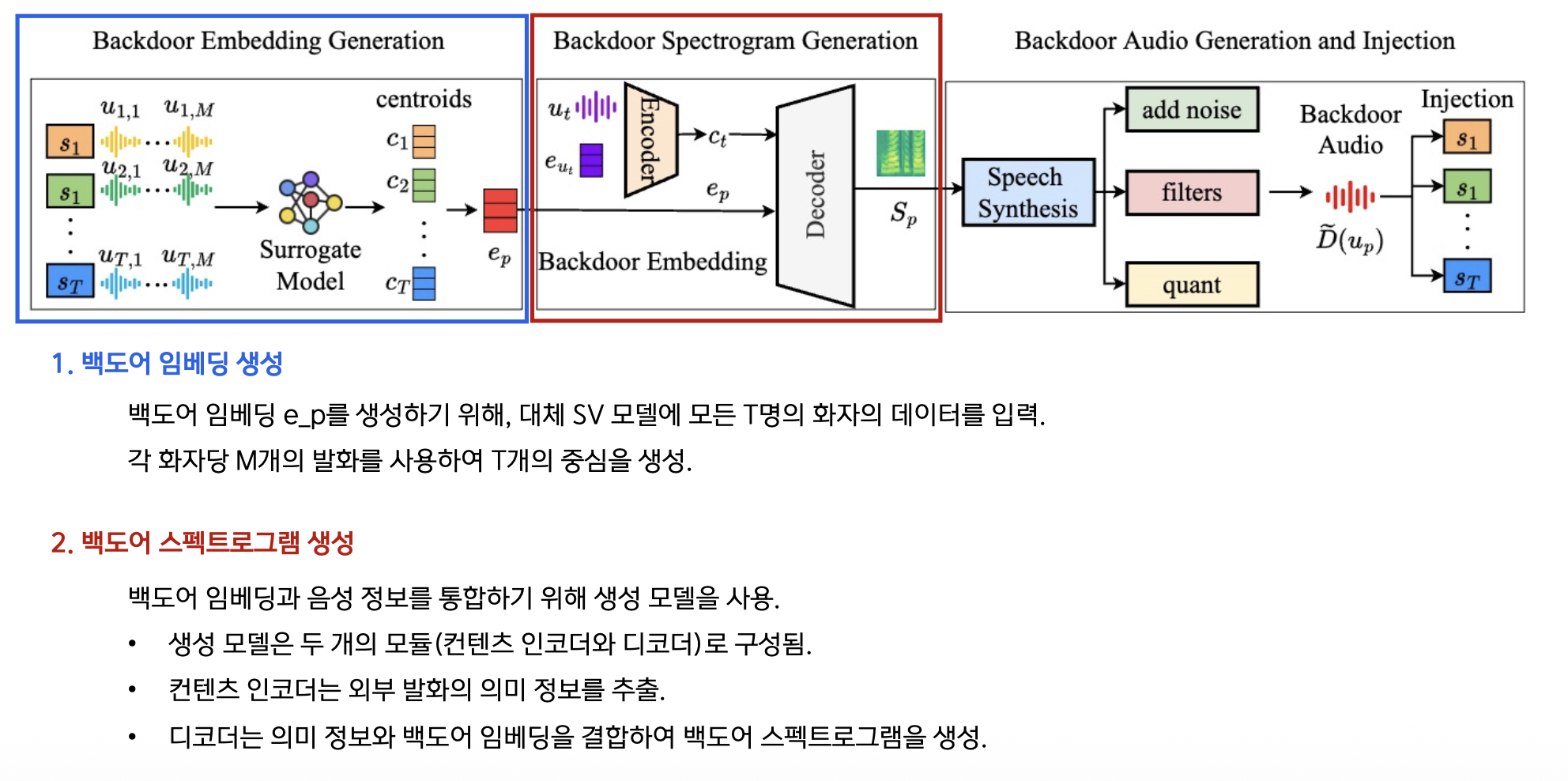 백도어 임베딩 및 스펙트로그램 생성
백도어 임베딩 및 스펙트로그램 생성
과정:
- 대체 SV 모델에 T명 화자 데이터 입력
- 각 화자당 M개 발화로 T개 중심 생성
- 최적화된 백도어 임베딩 $e_p$ 계산
Step 2: 백도어 스펙트로그램 생성
생성 모델 (2개 모듈):
- Content Encoder: 외부 발화의 의미 정보 추출
- Decoder: 의미 정보 + 백도어 임베딩 → 백도어 스펙트로그램
Step 3: 백도어 오디오 생성 및 채널 시뮬레이션
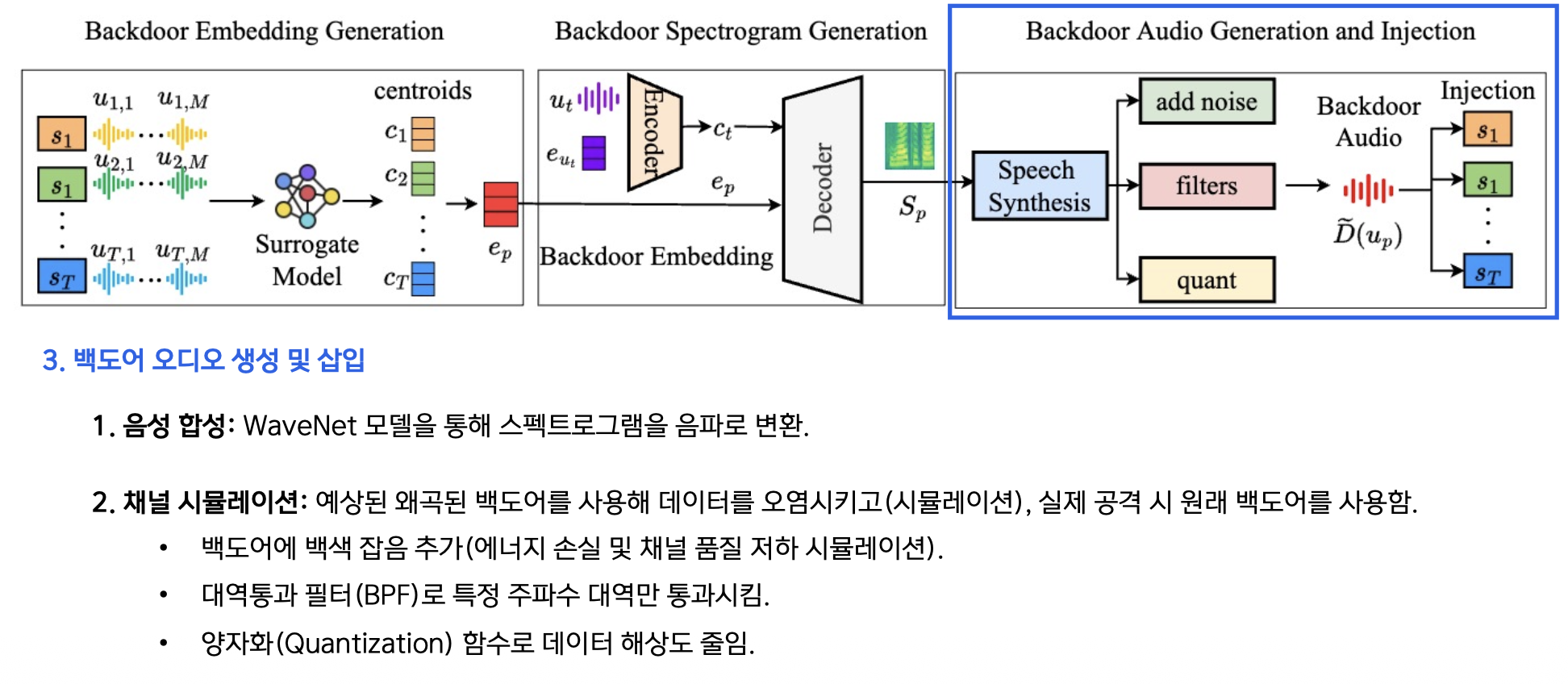 백도어 오디오 생성 및 채널 강건성
백도어 오디오 생성 및 채널 강건성
문제점:
- 스펙트로그램에 의미론적/구문론적 정보 부족
- 위상 정보 없음
- 실제 환경에서 오디오 품질 저하
해결 과정:
1️⃣ 음성 합성: WaveNet으로 스펙트로그램 → 음파 변환
2️⃣ 채널 시뮬레이션: 실제 환경 왜곡 모사
- 백색 잡음 추가 (에너지 손실 시뮬레이션)
- 대역통과 필터 (BPF)로 특정 주파수 대역만 통과
- 양자화로 데이터 해상도 감소
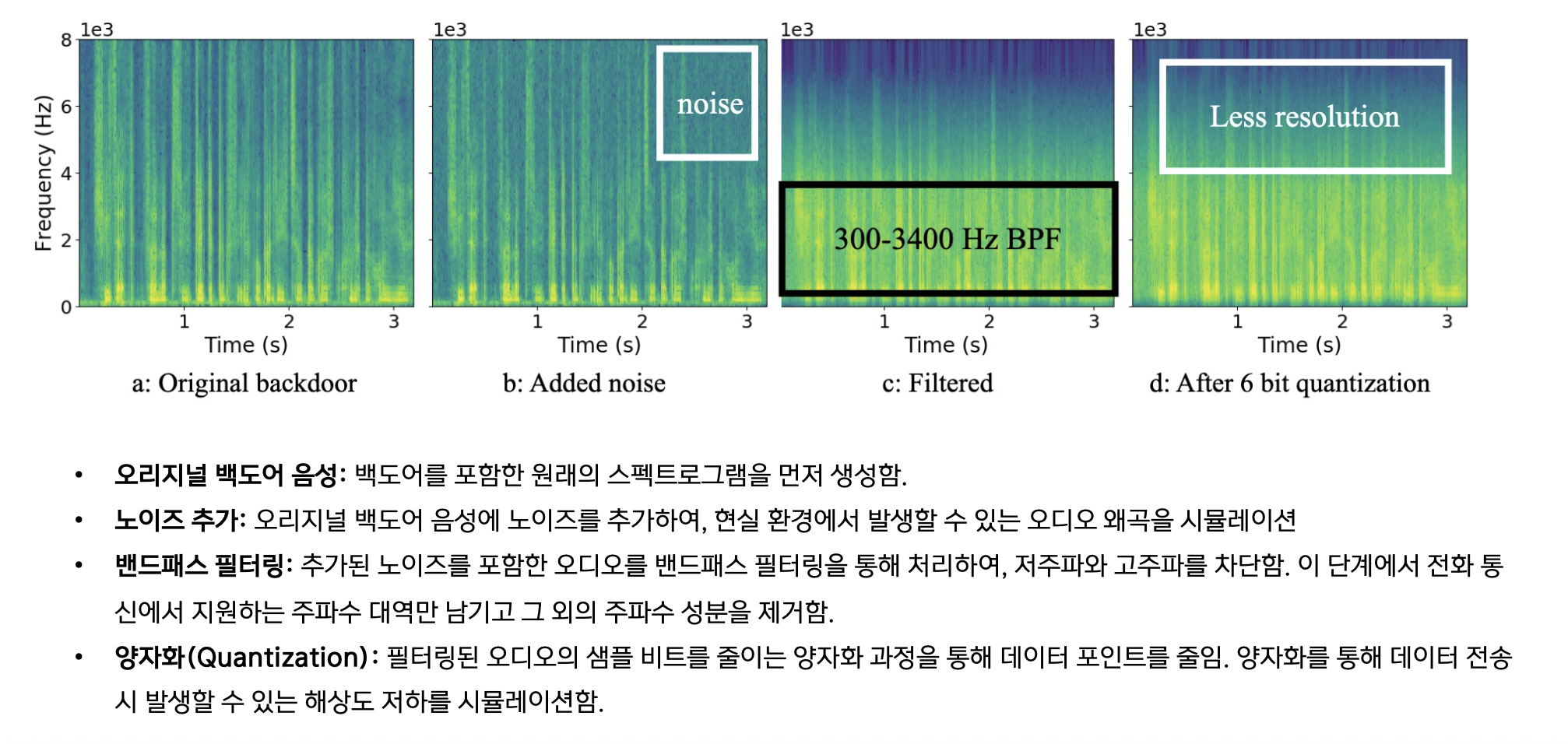 강건한 백도어 스펙트로그램 시각화
강건한 백도어 스펙트로그램 시각화
시뮬레이션 단계:
1
Original Backdoor → Add Noise → Bandpass Filter → Quantization
핵심: 훈련 시 왜곡된 백도어로 학습, 공격 시 원래 백도어 사용!
11. Evaluation: 실험 결과
Experiment Setup
사용 데이터셋:
| 데이터셋 | 규모 | 특징 |
|---|---|---|
| TIMIT | 630명 화자 6,300개 음성 | 각 발화 5-10초 길이 |
| LibreSpeech | 921명 화자 363.6시간 (23GB) | 대규모 공개 음성 데이터 |
실험 프로세스:
1
2
3
4
5
6
1. 6개 사전 학습된 SV 모델 다운로드 (정상 모델)
2. 독성 데이터셋으로 미세 조정 (poisoned model)
3. 두 데이터셋에서 20%를 OOD 타겟으로 선정
(훈련/독성 주입 단계에서 제외)
4. 오염된 모델에 OOD 타겟 등록
5. 백도어로 OOD 타겟 사칭 공격 시도
평가 지표:
- EER (Equal Error Rate): 모델 성능 지표
- False Accept Rate = False Reject Rate인 지점
- 낮을수록 좋은 모델
- ASR (Attack Success Rate): 공격 성공률
- 유사도 점수 ≥ 0.75면 공격 성공
- 높을수록 강력한 공격
- 유사도 점수: 코사인 유사도로 두 임베딩 간 거리 평가
- 1에 가까울수록 동일 화자로 인식
Benchmark Results
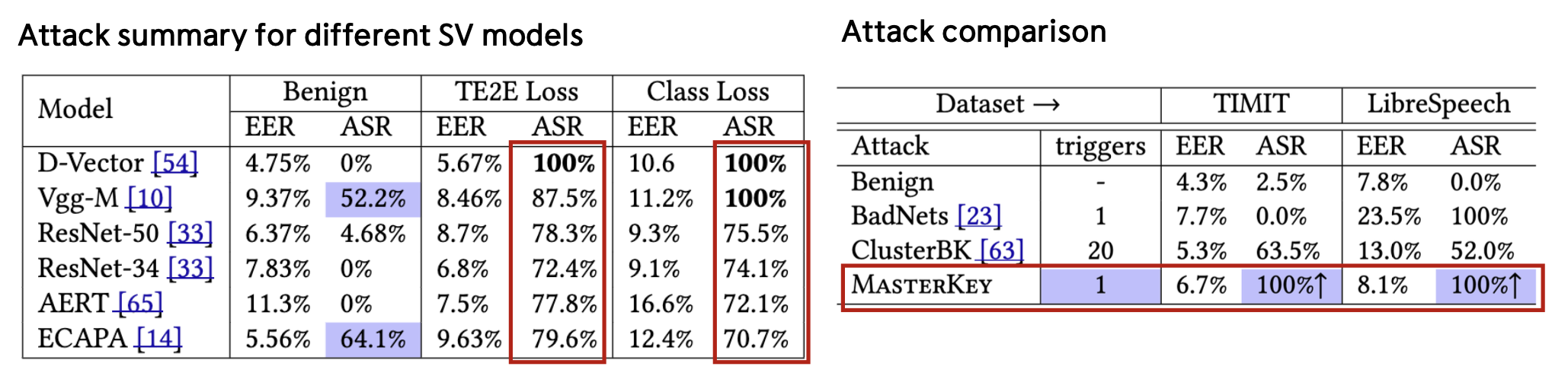 벤치마크 결과
벤치마크 결과
놀라운 발견:
- 정상 모델도 백도어 트리거 사용 시 Vgg-M과 ECAPA에서 ASR 50% 이상
- TE2E Loss로 조정된 모델: ASR 70% 이상, 정상 사용 시 낮은 EER 유지
기존 공격 대비 우수성:
- ✅ 더 적은 트리거
- ✅ 더 빠른 공격 시간
- ✅ 더 높은 ASR
Impact of Different Factors
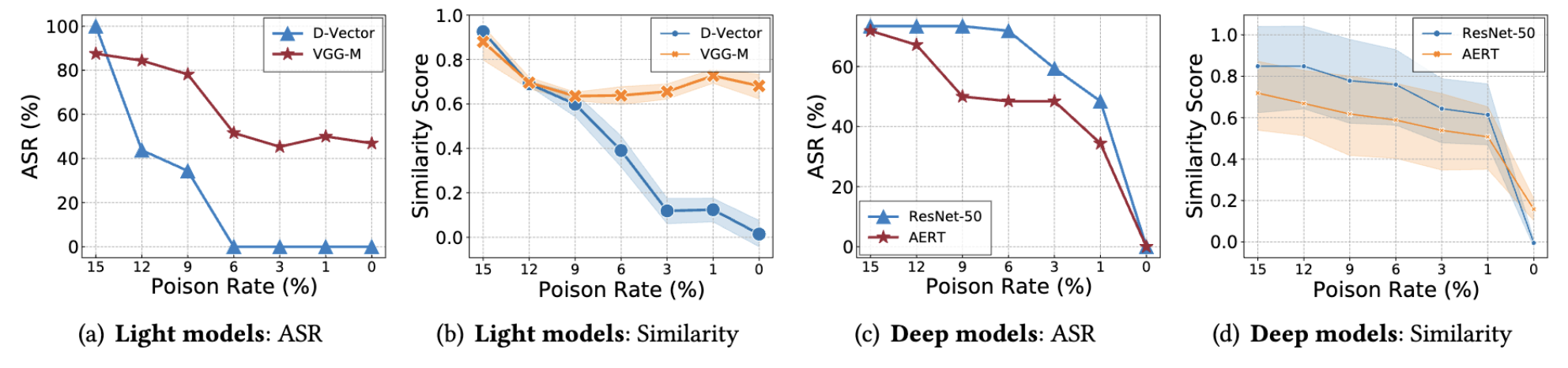 Poison Backdoor Rate 영향
Poison Backdoor Rate 영향
1. Poison Backdoor Rate (백도어 오염 비율)
- 15% → 1%로 감소 실험
- 영향은 있지만 모델 구조에 크게 의존
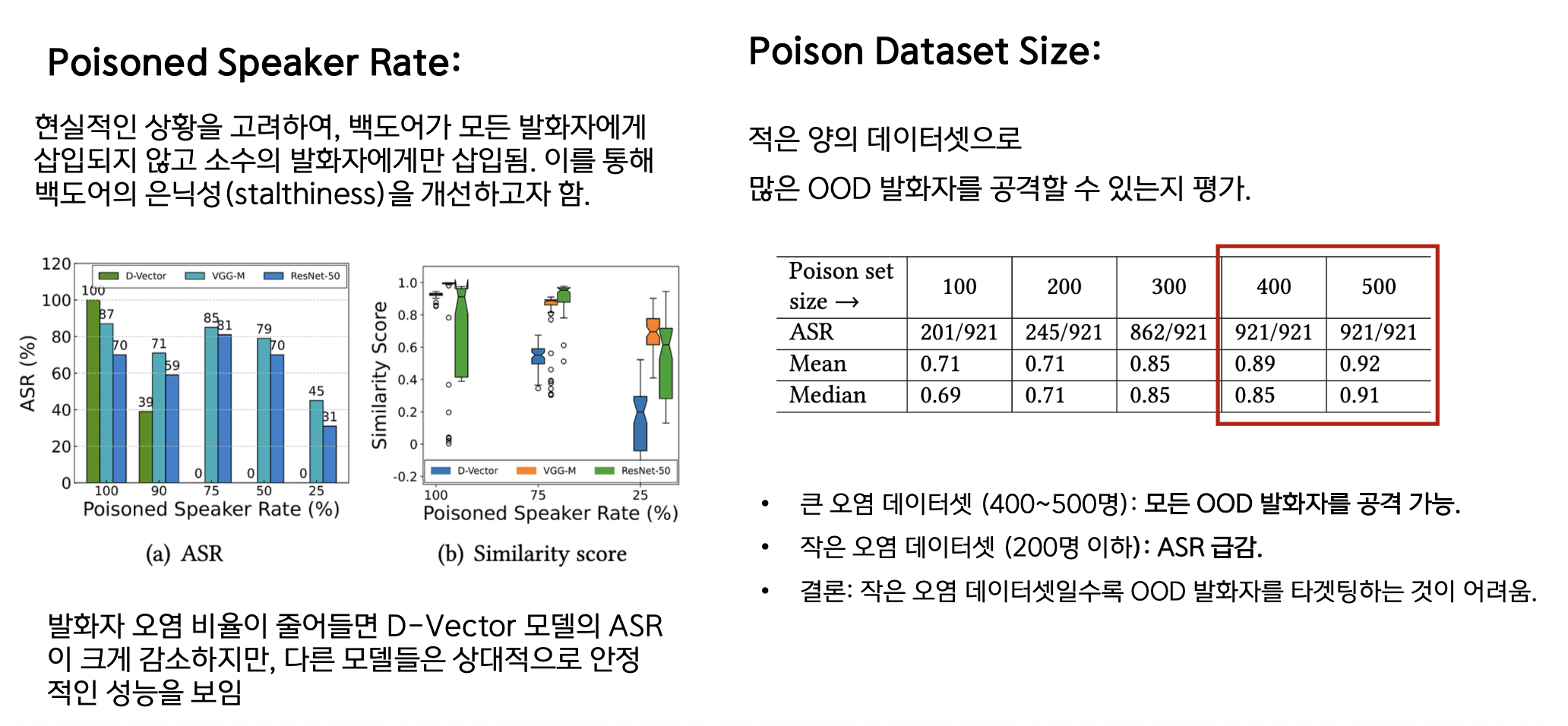 Poisoned Speaker Rate와 Dataset Size 영향
Poisoned Speaker Rate와 Dataset Size 영향
2. Poisoned Speaker Rate (발화자 오염 비율)
- 현실성을 고려해 소수 발화자에만 삽입
- D-Vector 모델은 ASR 감소, 다른 모델은 안정적
3. Poison Dataset Size (오염 데이터셋 크기)
- 큰 데이터셋 (400-500명): 모든 OOD 공격 가능
- 작은 데이터셋 (200명 이하): ASR 급감
결론: 작은 데이터셋일수록 OOD 타겟팅 어려움
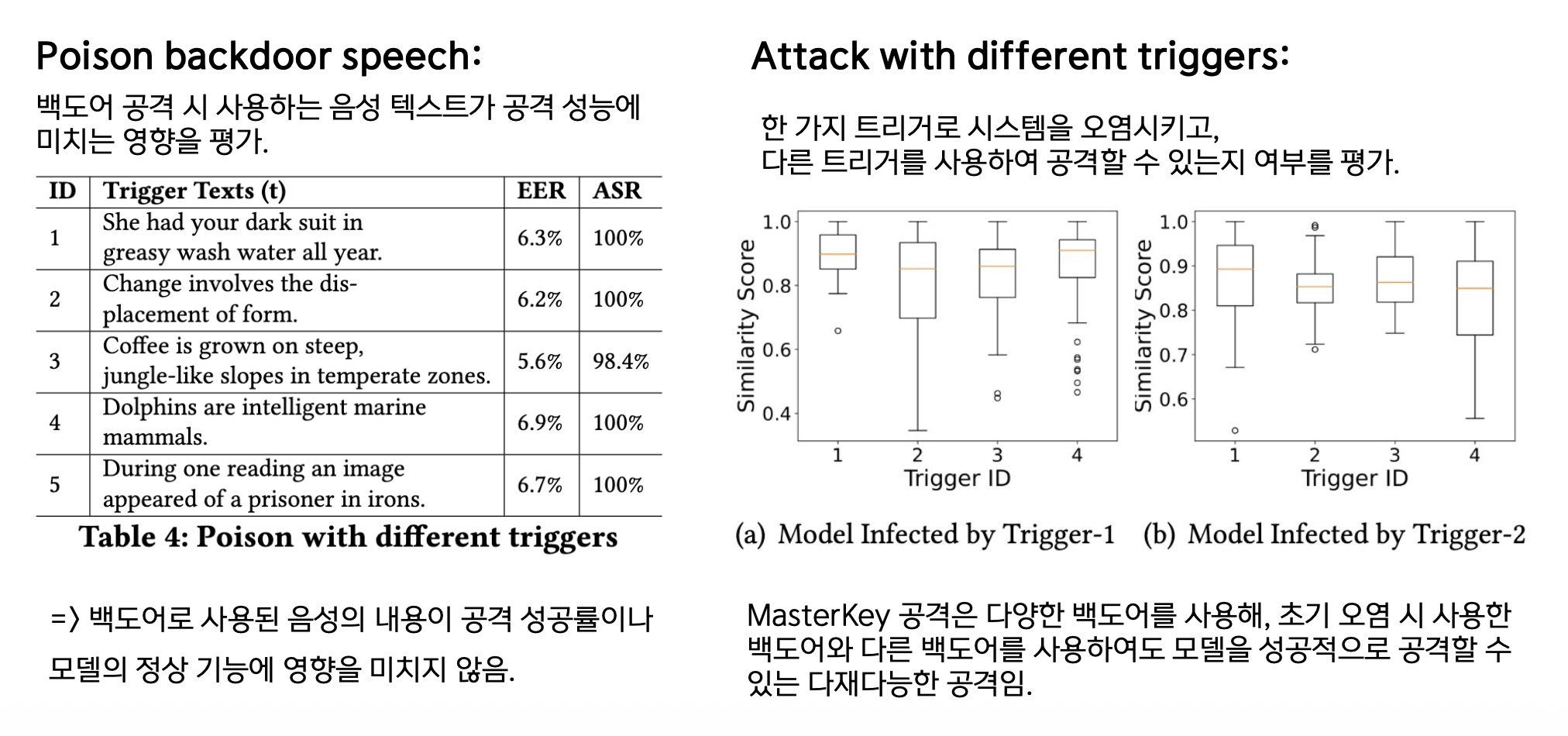 백도어 음성 및 트리거 다양성
백도어 음성 및 트리거 다양성
4. Poison Backdoor Speech (백도어 음성 내용)
- 음성 텍스트는 공격 성능에 영향 없음
5. Attack with Different Triggers (다양한 트리거)
- 다재다능함: 초기 오염과 다른 백도어로도 공격 성공!
12. Real-world Attack Scenarios
Over-the-Air Attack (무선 공격)
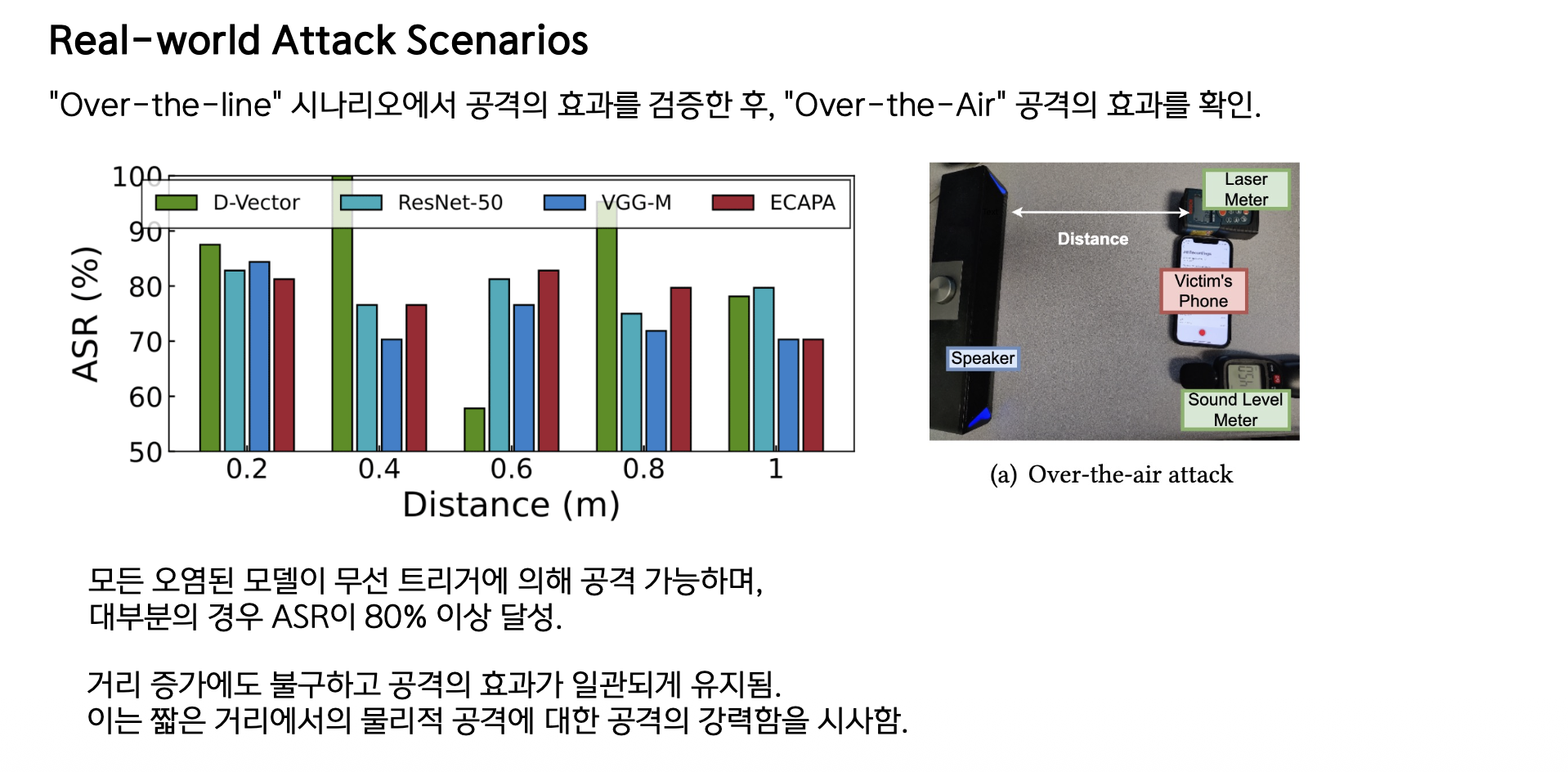 Over-the-Air 공격 결과
Over-the-Air 공격 결과
실험 설정:
- 다양한 거리에서 무선 트리거로 공격
결과:
- 모든 오염된 모델에서 공격 가능
- ASR 80% 이상 달성
- 거리 증가에도 효과 일관 유지
시사점: 짧은 거리 물리적 공격에 매우 강력함!
Over-the-Telephony-Network Attack (전화망 공격)
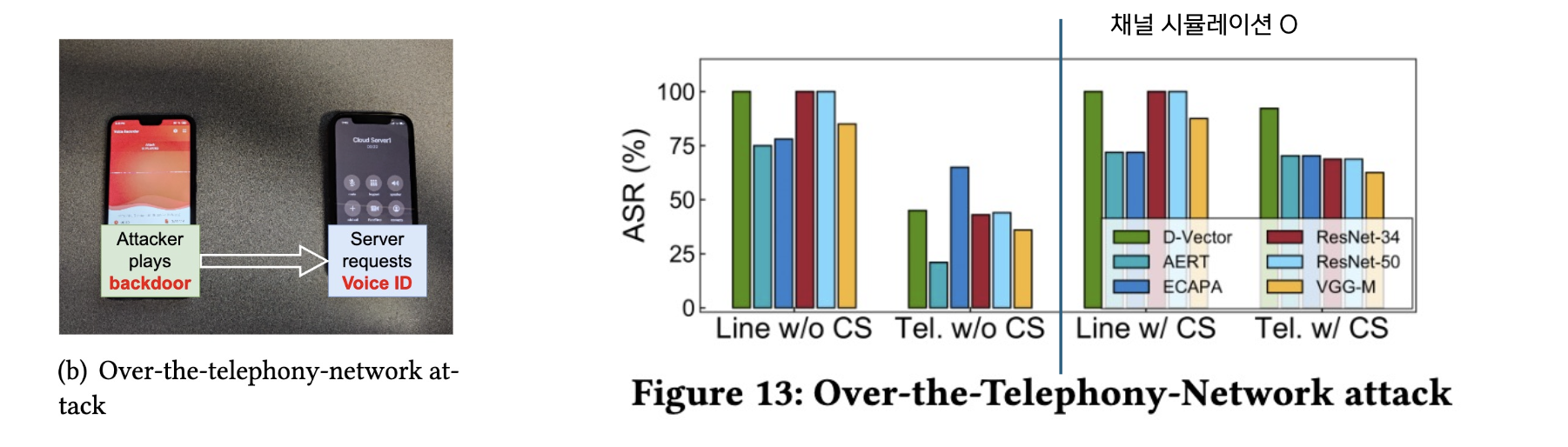 Over-the-Telephony 공격 결과
Over-the-Telephony 공격 결과
공격 시나리오:
- 공격자가 피해자 사용자명으로 클라우드 SV 시스템에 전화
- 전화 마이크에 백도어 오디오 재생
- 서버가 백도어 수집
결과 비교:
- Line (직접 공격): 채널 시뮬레이션 없으면 효율 감소
- Tel (통신망): 채널 시뮬레이션 있으면 ASR 80% 이상
핵심: 채널 시뮬레이션이 전화망 공격의 성공 열쇠!
13. Defense: Sniper 방어 메커니즘
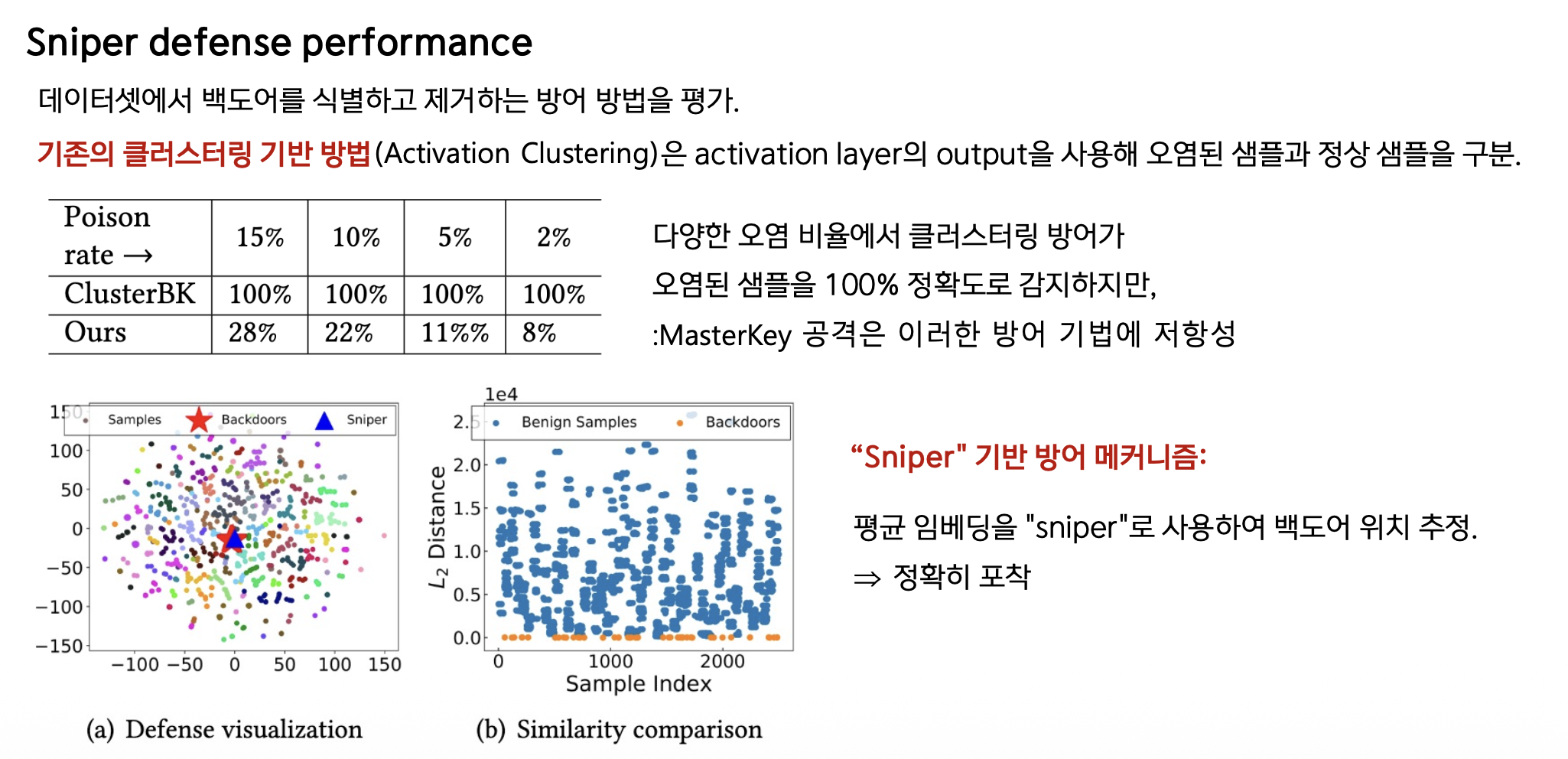 Sniper 방어 성능
Sniper 방어 성능
기존 방어의 한계
Activation Clustering:
- Activation layer output으로 백도어/정상 샘플 구분
- MasterKey에는 무용지물 ❌
- 이유: 백도어 샘플이 정상 데이터에서 파생되어 일반 정보 반영
Sniper 방어 메커니즘
핵심 아이디어:
\[\text{Sniper} = \frac{1}{N} \sum_{i=1}^N e_i\]- 모든 샘플의 평균 임베딩을 기준으로 삼음
- Sniper와의 거리 계산으로 백도어 식별
작동 방식:
- Sniper와의 거리가 임계값 $th_{d2}$ 이하인 샘플 → 백도어 의심
- Cleaner 알고리즘으로 자동 제거
성능:
- 다양한 오염 비율에서 백도어 정확히 포착 ✅
14. 논문의 의의 및 한계
주요 기여 🎯
- 최초의 실용적 OOD 백도어 공격
- 실제 환경(Over-the-Air, Over-the-Telephony)에서 검증
- 범용성
- 단일 백도어로 다수의 미지 사용자 공격
- 강건성
- 채널 시뮬레이션으로 다양한 통신 환경 대응
- 방어 메커니즘 제안
- Sniper 기반 효과적인 백도어 탐지
한계점 및 향후 연구 🔬
한계:
- 작은 데이터셋(<200명)에서는 ASR 급감
- 모델 구조에 따라 성능 차이 존재
향후 연구 방향:
- 더 적은 데이터로 효과적인 공격 방법
- Adaptive adversarial training 기반 방어
- 실시간 탐지 시스템 구축
15. 개인적인 생각 💭
인상 깊었던 점
- 실용성에 대한 집중
- 실험실이 아닌 실제 환경을 고려한 점이 훌륭함
- Over-the-Air, Over-the-Telephony 시나리오는 현실적
- 이론과 실험의 균형
- TE2E Loss Function 분석 → Poisoning Goal 설계 → 실험 검증
- 수학적 엄밀함과 공학적 실용성의 조화
- 방어 메커니즘 제안
- 공격만 하는 게 아니라 방어도 제안한 점이 책임감 있음
아쉬운 점
- Sniper 방어의 근본적 한계
- 평균 기반 방법은 adaptive attack에 취약할 수 있음
- 더 robust한 방어 메커니즘 필요
- 계산 복잡도 분석 부족
- 백도어 생성 및 채널 시뮬레이션의 계산 비용?
- 실시간 시스템 적용 가능성?
시사점
보안과 편의성의 트레이드오프
음성 인증은 편리하지만, 백도어 공격에 취약함을 보여줌.
중요한 시스템에는 다중 인증(Multi-factor Authentication) 필수!
참고 자료
함께 읽으면 좋은 논문
- Backdoor Attacks: BadNets, TrojanNN
- Speaker Verification: VoxCeleb, GE2E
- Adversarial ML: Audio Adversarial Examples
태그: #논문리뷰 #보안 #백도어공격 #음성인식 #딥러닝 #MobiCom