Paperprobe: RAG 기반 논문 Q&A 시스템 개발기
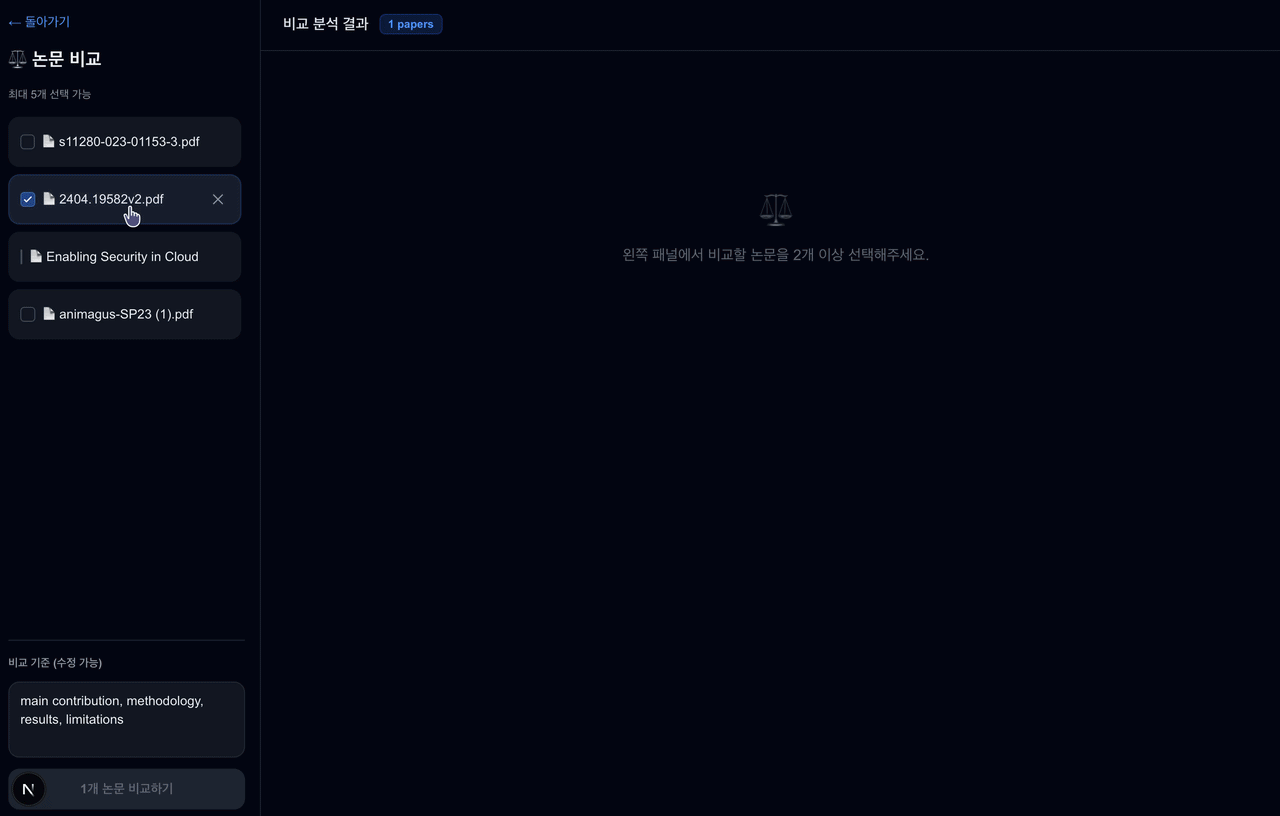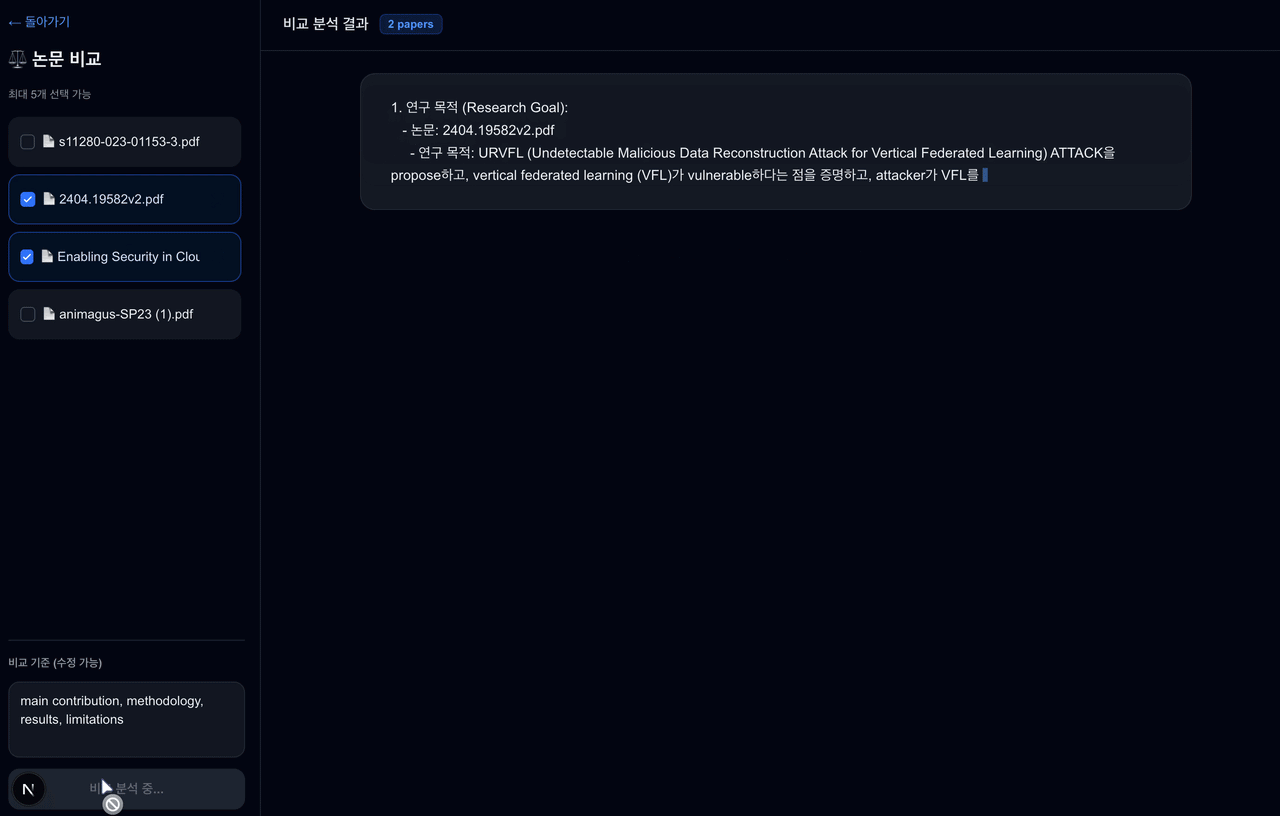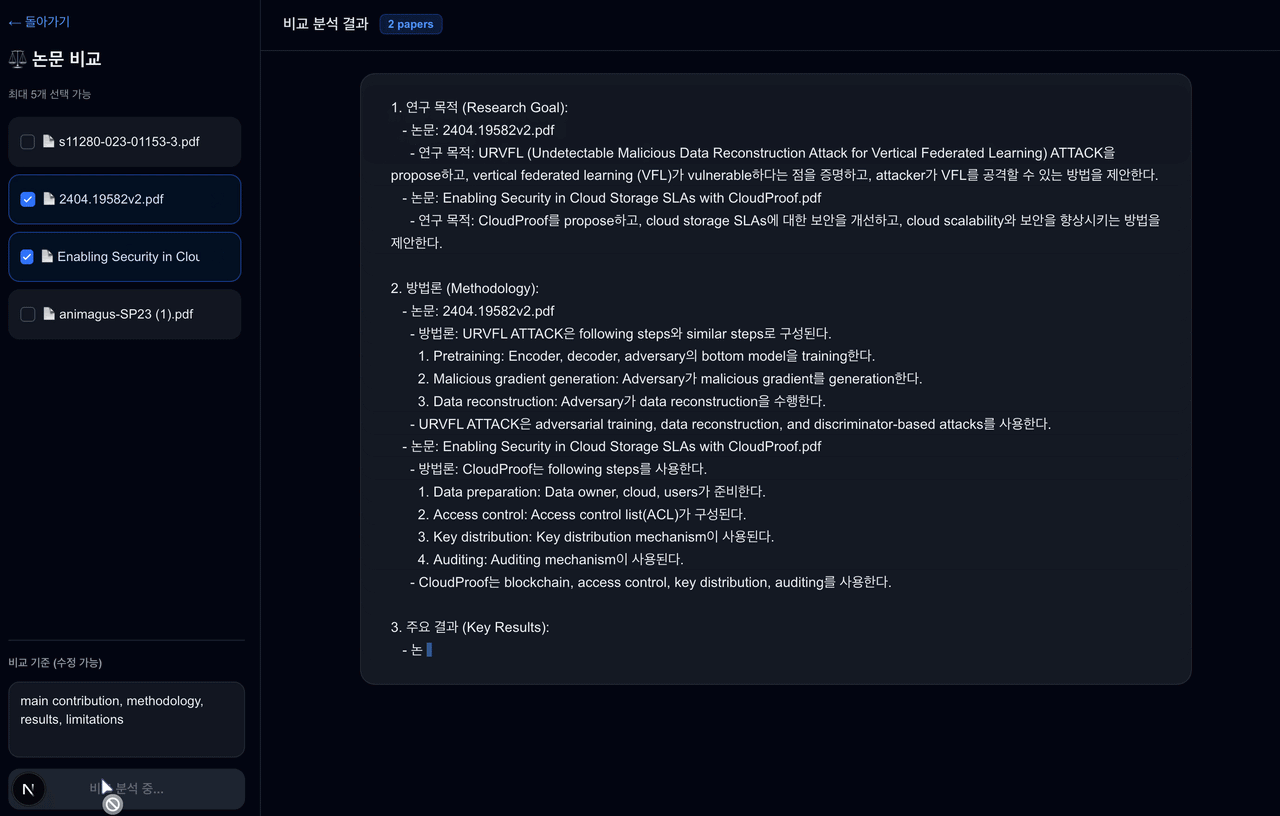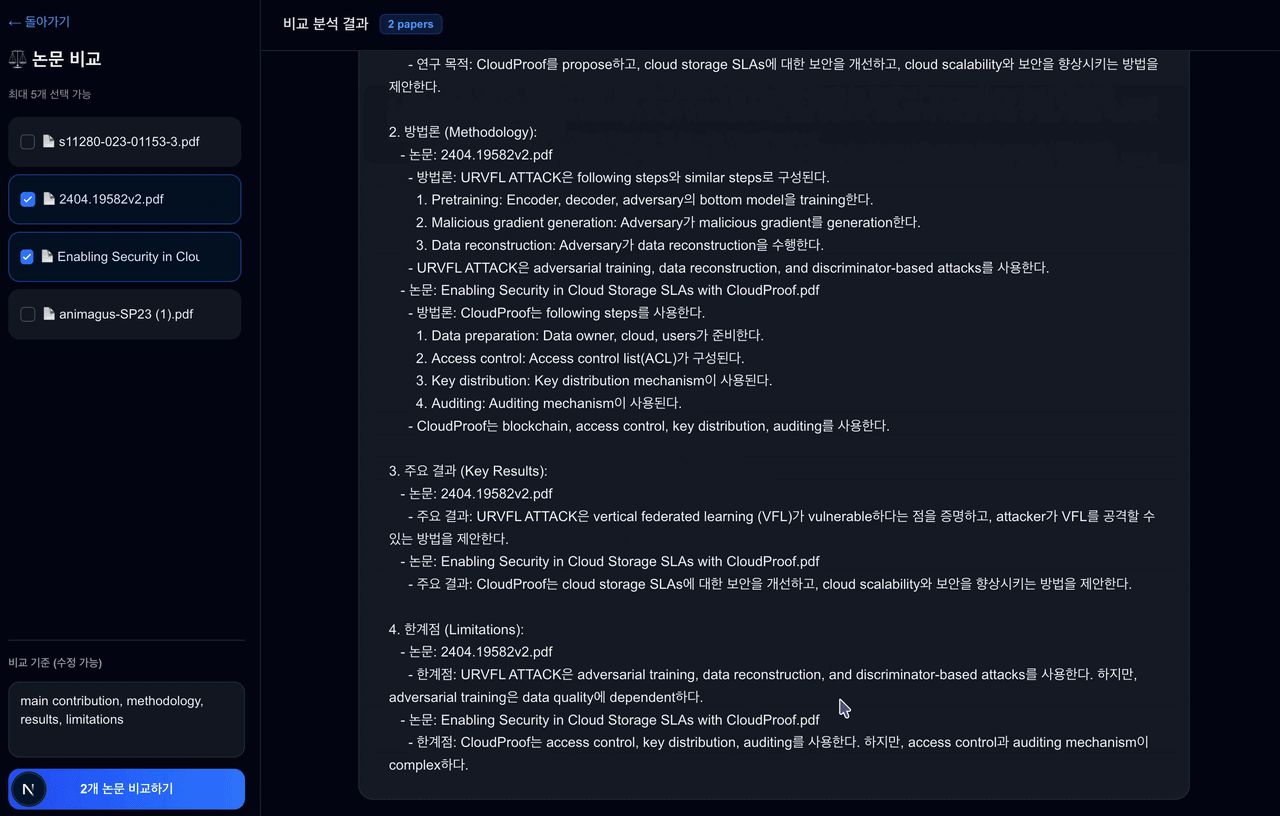
논문을 읽고 정리하는 과정이 생각보다 많은 시간을 차지한다.
요즘은 LLM이 논문 정리를 꽤 잘해주고, 관련 도구들도 많이 등장했다. 그럼에도 불구하고 논문을 읽고 정리하는 과정에는 여전히 반복적인 작업이 많다. 그래서 이 일련의 과정을 조금 더 자동화할 수 있지 않을까 하는 생각이 들었다.
사실 필요보다는 재미로 시작한 측면이 크다. AI 보안을 연구하는 입장에서 Prompt Injection 탐지까지 붙여보면 재밌겠다고 생각했다.
왜 만들었나
연구실에서 논문을 읽는 루틴은 대략 이렇다. PDF를 열고, 훑고, 필요한 부분을 찾아 다시 돌아가고, 메모하고, 또 찾고. 논문 한 편을 제대로 소화하려면 같은 문서를 수십 번 왔다갔다 하게 된다. 논문이 쌓일수록 이 비효율은 배가된다. 특히 몇 주 전에 읽은 논문에 대해 찾아보려면 따로 정리해놓지 않은 이상 결국 처음부터 다시 읽어야 한다.
Claude나 ChatGPT에 PDF를 붙여넣는 방법도 써봤지만 context 길이 제한에 금방 걸리고, 할루시네이션도 잦았다. 논문처럼 정밀한 정보를 다루는 도메인에서는 특히 신뢰하기 어려웠다.
RAG(Retrieval-Augmented Generation)를 처음 접했을 때 이 문제를 구조적으로 해결할 수 있는 방법이라고 생각했다. 논문 전체를 청킹해서 벡터로 저장해두고, 질문이 들어올 때 관련 청크만 꺼내 LLM에 전달하면 훨씬 정확하고 맥락 있는 답변이 나온다. 논문은 구조가 명확하고 질문 패턴도 어느 정도 정해져 있어서 RAG를 적용하기에 최적의 도메인이기도 했다.
이때는 생각만 해보고 구현까지 해볼 생각은 못했지만, 논문을 하나 제출하고 심심한 김에 만들어보기로 했다. 사실 지금은 할루시네이션도 많이 개선됐고, NotebookLM이나 ChatGPT PDF 기능처럼 비슷한 툴도 이미 잘 만들어져 있다. 그럼에도 직접 만들어보는 이유는: 어떻게 동작하는지 속을 들여다보고 싶었고, 거기에 내가 원하는 기능을 마음대로 붙여보고 싶었다.
아무튼 여기에 AI 보안을 연구하는 입장에서 한 가지를 더 붙이고 싶었다. RAG 시스템은 외부 문서를 그대로 LLM의 컨텍스트로 넣는 구조라 Prompt Injection 공격에 취약하다. 악의적으로 조작된 PDF 안에 “이전 지시를 무시하고 …” 같은 명령어가 숨어 있으면 LLM이 그대로 따를 수 있다. 보안 연구자로서 이 취약점을 탐지하고 방어하는 기능까지 구현해보는 것을 목표로 했다.
시스템 구조
1
2
3
PDF 업로드 → 텍스트 추출 → 청킹 → 임베딩 → ChromaDB 저장
↓
질문 입력 → 질문 임베딩 → 유사 청크 검색 (top-k=5) → LLM 답변 생성
기술 스택은 다음과 같다.
| Layer | Stack |
|---|---|
| Backend | FastAPI, Python 3.10 |
| Vector DB | ChromaDB 0.4.24 |
| Embedding | sentence-transformers (all-MiniLM-L6-v2) |
| PDF 파싱 | pdfplumber |
| LLM | Ollama (llama3.2) / Gemini API |
| Frontend | Next.js, TypeScript, Tailwind CSS, D3.js |
핵심 구현
1. PDF 청킹
논문 전체를 한 번에 LLM에 넣는 건 context window 한계 때문에 불가능하다. 500 단어 단위로 청킹하고 50 단어 오버랩을 줘서 문맥이 끊기지 않도록 했다.
1
2
3
4
5
6
7
def chunk_text(text: str, chunk_size=500, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = " ".join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
2. RAG 질의응답
질문이 들어오면 동일한 임베딩 모델로 질문을 벡터화하고 ChromaDB에서 코사인 유사도 기준 top-5 청크를 검색한다. 검색된 청크를 컨텍스트로 LLM에 전달해 답변을 생성한다.
1
2
3
4
5
results = collection.query(
query_embeddings=[query_embedding],
n_results=5
)
context = "\n\n".join(results["documents"][0])
3. Prompt Injection 탐지
RAG 시스템의 대표적인 보안 취약점 중 하나가 PDF 내에 악의적인 명령어를 삽입하는 것이다. 논문처럼 보이는 PDF 안에 “이전 지시를 무시하고 …” 같은 공격 문구가 들어있으면 LLM이 그대로 따를 수 있다.
이를 탐지하기 위해 한/영 혼합 공격 예시 문장 18개를 all-MiniLM-L6-v2로 임베딩해두고, 업로드된 PDF의 각 청크와 코사인 유사도를 비교했다.
1
2
3
4
5
6
7
8
9
10
11
THRESHOLDS = {"high": 0.7, "medium": 0.5, "low": 0.35}
def detect_injection(chunks):
suspicious = []
for chunk in chunks:
chunk_emb = model.encode(chunk)
for example_emb in INJECTION_EXAMPLES_EMB:
sim = cosine_similarity(chunk_emb, example_emb)
if sim >= THRESHOLDS["low"]:
suspicious.append({"chunk": chunk, "score": sim})
return suspicious
모든 쿼리에는 방어 문구를 자동으로 앞에 붙여서 LLM이 공격에 반응하지 않도록 했다.
4. 논문 유사도 그래프
논문별로 청크 임베딩의 평균을 구해 대표 벡터를 만들고, 논문 간 코사인 유사도를 계산해 D3.js force simulation으로 시각화했다. 유사도 0.3 이상인 논문 쌍만 엣지로 연결한다.
트러블슈팅
Ollama “wrong number of tensors” 에러
brew로 설치한 Ollama 버전이 오래돼서 발생한 문제였다. 공식 스크립트로 재설치하니 해결됐다.
1
2
brew uninstall ollama
curl -fsSL https://ollama.com/install.sh | sh
D3.js clientWidth null 에러
SVG 요소가 DOM에 마운트되기 전에 D3 코드가 실행되는 타이밍 문제였다. SVG를 항상 DOM에 유지하고 setTimeout으로 그리기를 지연시켜 해결했다.
ChromaDB + Security 404
보안 모듈 추가 전에 업로드된 논문은 청크에 메타데이터가 없어서 발생했다. chroma_db와 paperprobe.db를 삭제하고 재업로드하면 해결된다.
마치며
RAG 파이프라인 자체는 생각보다 빠르게 구현됐지만, 보안 모듈과 그래프 시각화를 붙이면서 예상치 못한 버그들을 많이 만났다. 특히 Prompt Injection 탐지는 임계값 튜닝이 까다로웠다. 너무 낮으면 오탐이 많고, 너무 높으면 실제 공격을 놓친다.
다음 프로젝트인 PaperMesh에서는 arxiv API 연동과 PostgreSQL을 써볼 예정이다. 논문 검색부터 Q&A까지 이어지는 파이프라인을 만들어보려 한다.
📎 GitHub: github.com/nahyun27/paperprobe